
最近有一篇报道,如下:
“英伟达最新的Blackwell AI芯片在服务器部署中遇到严重的散热问题。这个问题可能影响包括Meta、Google和Microsoft在内的主要客户的数据中心建设计划。”
即使有这些问题,英伟达基于Blackwell芯片的NVL平台依然在供不应求的出货中。没有办法,云厂商们对AI算力需求太渴望了,即使散热带病出征。
尽管B200仍在出货爬坡中,但一些CSP(超大规模云)厂商已经开始与供应链互动B300。B300(Blackwell Ultra)正如其名,是B200的升级版本。其三个关键更新:
首先是使用x86 CPU的替代方案,这表明仍然需要PCI-E接口(和相关组件)。
其次是电源–超级电容器和BBU(Battery Backup Unit)(如UPS)的引入旨在解决电源问题。
第三是更灵活地决定零部件供应商。
第一点的意思是:可以不使用英伟达自己家的Grace CPU,而使用其他家的CPU。而其他家的CPU的外设接口用的是PCIe接口;
第二点的意思是:机架的功耗增加需要超级电容来做备份。(电池本质上就是一个充放电时间很长的电容)。那为什么以前不需要,现在需要呢?不就是因为功耗增加了,要求运算峰值的时候爆发一把,非峰值的时候就蓄电。
第三点的意思是上游零部件供应商可以有更多地灵活选择。对非一供的厂商有利。
这三点展开谈都可以谈很多,我今天重点说说第二点功耗及相关。
正如上面报道所言,电源给服务器供电,但是并不是所有的能量都百分之百用于正途(计算、传输或者存储),电子之间的碰撞不可避免就产生了热。能量真正有效比例就是效率,集成电路的效率。效率和CMOS材料有关,集成电路工艺可以升级,但是效率却基本无法提升。因为工艺升级并没有改变材料。总输入的能量或者功耗增加了,效率没有改善,意味着耗散出来的热量必然就会增加。
B300是B200的升级版本,所以B200出现的严重散热问题在B300不但仍然存在,而且会更加严重。
这一点成为AI硬件当前最大难点。毫无疑问,谁能解决这个难点,谁就有价值。
对于散热,我认为当前市场有着极大的误解。他们心目中的散热难点是芯片壳体温度降到环境温度;然而,真实的难点是:芯片封装内部die到芯片壳体+芯片与芯片之间的热串扰。
这个难点已经严重困扰了整个产业界,以致于在今年OCP(开放计算平台组织)会议上作为最重要的话题拿出来讨论。
为什么不是以前,而是今年成为业界的聚焦点?本质上还是因为GPU的高算力及GPU配套的高存储、高传输。过去CPU时代不成为问题的问题,现在因为GPU功耗快速增速而成为显著问题。
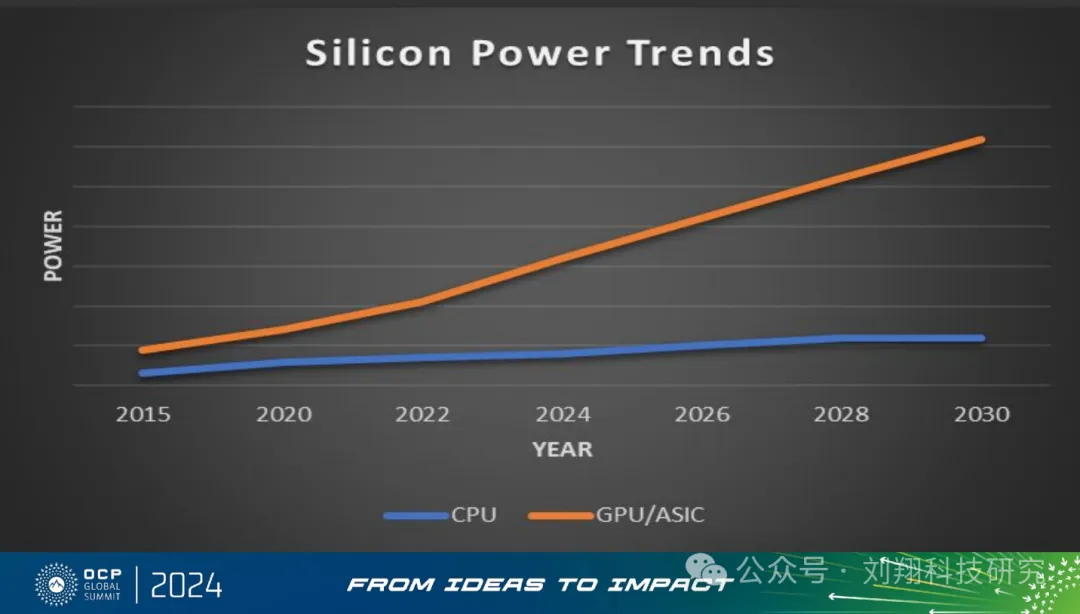
GPU的出现让散热问题越来越突出,这点很好理解。但其实散热分为两部分:第一部分是芯片弱晶圆die到芯片封装外壳;第二部分是芯片封装外壳到环境温度。
正如以下这个ppt所言,第二部分可以很好解决,真正的难点是第一部分:晶圆die到芯片封装外壳以及芯片与芯片之间的热串扰。

上面PPT的右下角柱状图表的两支,左边是ASIC(专用集成电路),右边是HBM。HBM中芯片封装内部热阻抗(蓝色部分)占比73%,明显高于AISIC的蓝色部分,就是说HBM散热要求更高。为啥HBM散热要求高?道理很简单,8层或12层或者16层叠在一起肯定发热更多嘛。

这些散热要求不仅仅在芯片内部、芯片和散热片之间,也同样在芯片与中间层(interposer)的内部与之间,interposer与载板的内部与之间、载板与PCB的内部与之间。这也是业内探讨用玻璃材质取代硅晶圆来做interposer的理由之一。
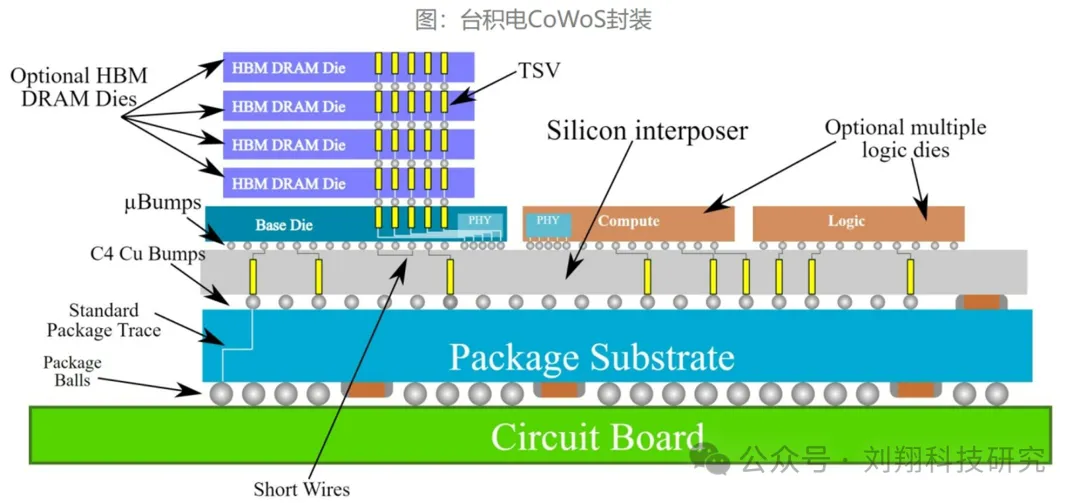
更有未来不论是硅光还是其他,集成是大趋势。HBM、GPU、还有其他的芯片都封装在一起,这里面芯片之间的串热和散热搅在一起,散热的要求就更高了。如下图这就是台积电未来的COWOS封装方案,整合在一起,统统整合到一个芯片里面。
事实上,确实如此。英伟达的下一代GPU,Rubin就要将自己家设计的CPU、GPU整合到一起。Blackwell的下一代Rubin方案主要特点如下:
内存和带宽:Rubin架构的GPU将支持12层HBM4堆栈,而Rubin Ultra将支持16层HBM4堆栈,这将显著提升内存容量和带宽,为AI和高性能计算提供更强的数据吞吐能力
CPU集成:与Rubin GPU一同公布的还有名为Vera的新型CPU,该CPU将被集成在名为Vera Rubin的加速卡上,形成超级芯片,这标志着NVIDIA在CPU领域的进一步扩展。
网络性能:Rubin平台采用了NVLink 6交换机,其速度高达3,600 GB/s,以及CX9 SuperNIC组件,提供高达1,600 GB/s的速率,这将极大地提升数据中心内部的数据传输效率。
性能与效率:Rubin架构的GPU预计将在性能上实现代际飞跃,同时更加注重降低功耗,能效比将成为一个重要的考量因素。
简言之,今天用于HBM的散热相关方案,明后年就将复制到GPU、网络、硅光芯片方案中,这会是10倍以上的增量。
那么HBM是怎么做散热的呢?我们来看看全球HBM龙头厂商SK-海力士的做法。

Sk-海力士很明确的指出,他们家的HBM之所以全球领先,就靠两个核心东西:1.Chip warpage control(晶圆卷曲控制技术);2.Gapfill-MUF material(空隙填充材料),其中填料就决定了芯片的可靠性(散热不好芯片可靠性就差)。
MR-MUF是Mass Reflow Molded Underfill的缩写,用汉语词汇不是很好翻译概括,简单描述就是通过在高温下将填充材料流动到芯片和基板之间,实现高效的封装和散热的技术,通常采用填料提高机械强度和热导率,并减少内应力(芯片翘曲)。散热和增强填料以氧化铝、氮化硼、硅微粉、玻璃纤维较为常见,更多特殊填料则可能涉及个性化需求或特殊配方。而所谓新一代MR-MUF是SK海力士发现传统MR-MUF在面对更密集堆叠时(从8层到12层),在散热和芯片翘曲问题上已力不从心。也就是说对填料的性能又提出了更高要求。
就怕没要求。有要求就有价值。同样是氧化铝、氮化硼、硅微粉、玻璃纤维这些粉体材料,不同场合和要求下,粉体价格可以差上1000倍。
真正能解决最棘手的散热问题,靠的是这些高端填料。这就是最值得重视的投资方向!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}